
Autori: Lorenzo Di Giulio Cesare, Nadiya Lesiv, Saverio Del Magno, Maristella Martinello, Sara Miozzi, Roberta Serra.
Lanciato nel 2006, Twitter è tra i più importanti social network e un formidabile laboratorio di analisi semantica e sociale, grazie alla possibilità di accedere a milioni di contenuti generati ogni giorno da più di 300 milioni di persone in tutto il mondo.
Metodi e strumenti
La fonte dati primaria è l’Internet Archive, in particolare un sottoinsieme dei tweet prodotti a settembre 2019 (stima del volume: circa 4 mila tweet al minuto). I dati sono organizzati in collezioni di file jsonl compressi (bzip2).
Uno script Python prodotto legge tutti i file .bz2 nella cartella di input ed estrae i dati di frequenza e co-occorrenza di hashtag e utenti (autori dei tweet, dei retweet e menzioni). Due hashtag sono collegati quando compaiono insieme nello stesso tweet. Due utenti sono collegati quando sono menzionati insieme nello stesso tweet e quando un autore menziona un altro utente nel proprio tweet. Sia i nodi (hashtag e utenti) che gli archi (hashtag-hashtag e utente-utente) sono pesati in base alla frequenza.
Nodi e archi per hashtag e utenti sono salvati separatamente in 4 file. Importandoli in Gephi si ricostruiscono le reti semantiche (hashtag) e quelle sociali (utenti) relative all’intervallo temporale selezionato. Per generare le immagini che seguono sono stati applicati opportuni filtri sia sui nodi (degree range), sia sugli archi (edge weight) per semplificare le reti. La dimensione dei nodi è proporzionale alla loro frequenza, così come lo spessore degli archi. Gli algoritmi di layout ForceAtlas2 e Fruchterman Reingold con una scelta ad hoc dei parametri hanno permesso una visualizzazione più chiara delle reti, in particolare delle componenti connesse. In alcuni casi sono state calcolate esplicitamente mediante l’applicazione dell’algoritmo di analisi Connected Components e l’applicazione di una colorazione opportuna (Appearance > Nodes > Color > Partition > Component ID). Gli orari indicati si riferiscono al fuso della costa est degli Stati Uniti.
Risultati
Roberta
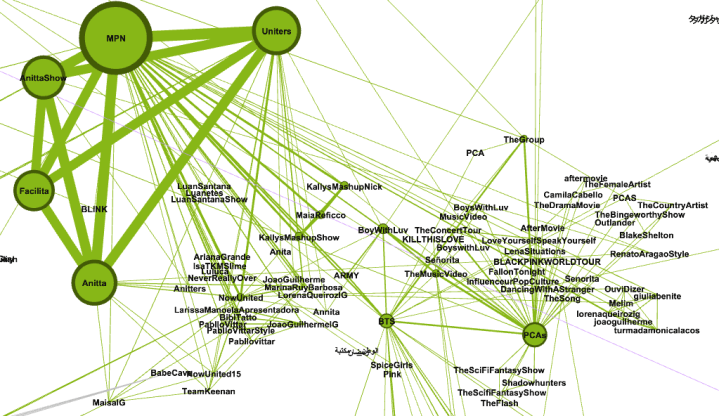
Maristella
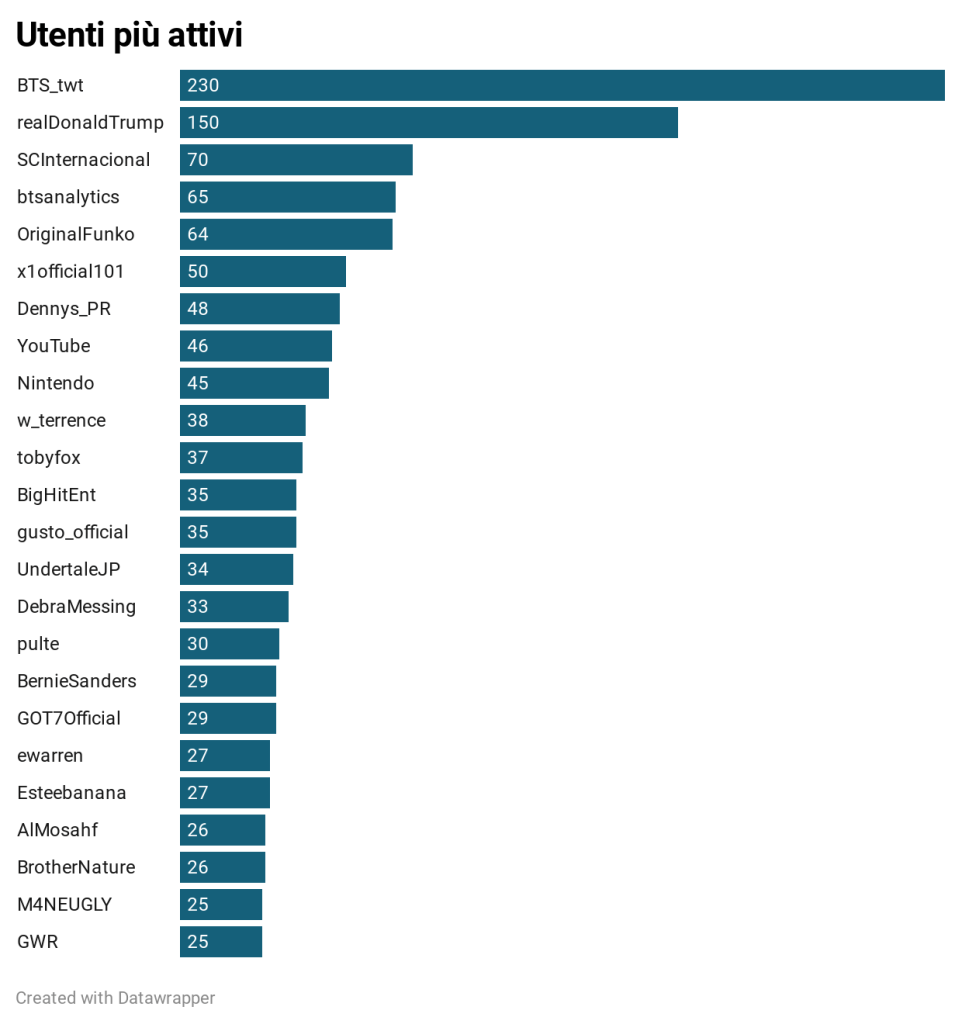
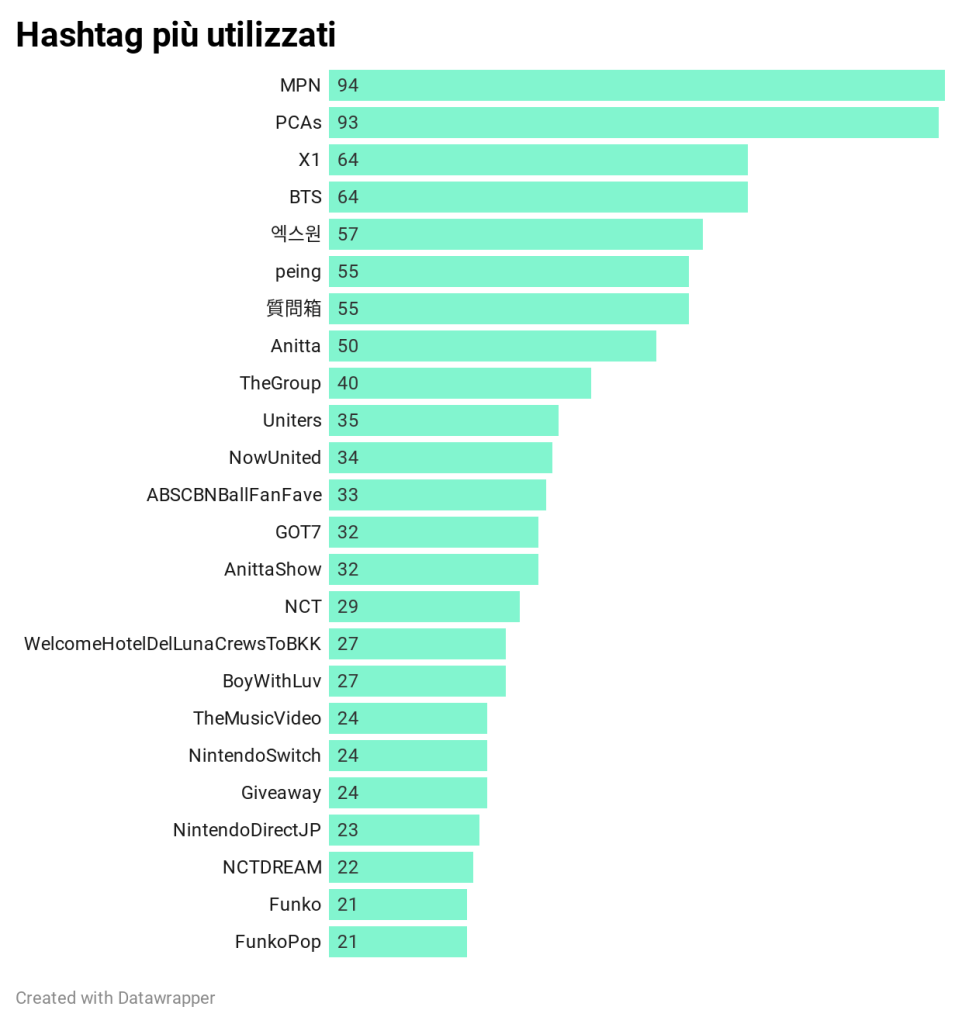
Lorenzo
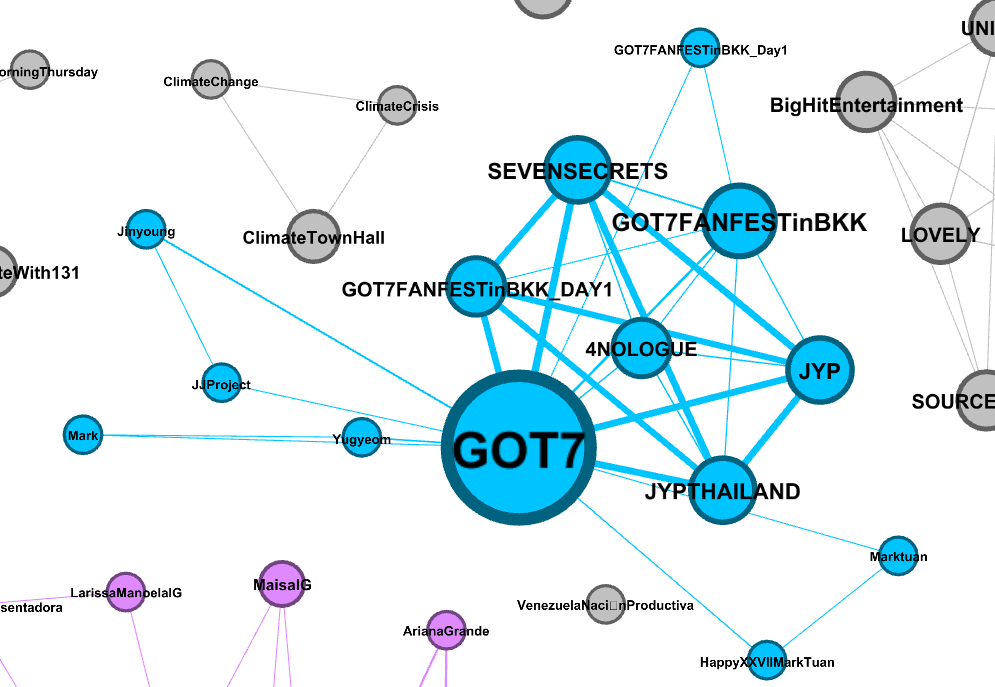
Sara
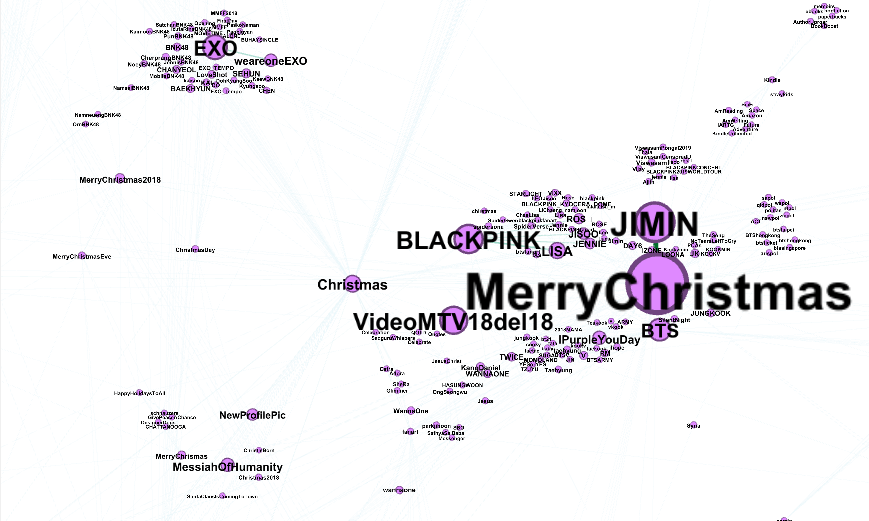
Saverio

Nadiya

Codice sorgente e dati
L’applicazione è scritta in Python 3, il codice sorgente è rilasciato con licenza di pubblico dominio (CC0) ed è scaricabile da Google Drive.
Uso: python main.py /path/to/bz2/directory/.
I file dati in formato compresso .bz2 sono scaricabili da Internet Archive (ecco un esempio). In output il programma genera 4 file .csv da importare in Gephi: hashtags_nodes.csv, hashtags_edges.csv, users_nodes.csv, users_edges.csv.
# Twitter hashtags and users counter
import sys
import bz2
import json
from pathlib import Path
input_directory = Path(sys.argv[1])
hashtags_nodes = {}
hashtags_edges = {}
users_nodes = {}
users_edges = {}
for input_filename in input_directory.glob("**/*.bz2"):
with bz2.open(input_filename, "rb") as f:
for line in f:
tweet = json.loads(line)
if "delete" in tweet:
continue
if "extended_tweet" in tweet:
tweet_hashtags = tweet["extended_tweet"]["entities"]["hashtags"]
tweet_mentions = tweet["extended_tweet"]["entities"]["user_mentions"]
else:
tweet_hashtags = tweet["entities"]["hashtags"]
tweet_mentions = tweet["entities"]["user_mentions"]
# Calcolo le occorrenze degli hashtag
for hashtag in tweet_hashtags:
hashtag_text = hashtag["text"]
if hashtag_text not in hashtags_nodes:
hashtags_nodes[hashtag_text] = 1
else:
hashtags_nodes[hashtag_text] += 1
# Calcolo le occorrenze delle menzioni
for mention in tweet_mentions:
screen_name = mention["screen_name"]
if screen_name not in users_nodes:
users_nodes[screen_name] = 1
else:
users_nodes[screen_name] += 1
# Calcolo le occorrenze dell'autore del tweet
screen_name = tweet["user"]["screen_name"]
if screen_name not in users_nodes:
users_nodes[screen_name] = 1
else:
users_nodes[screen_name] += 1
# Calcolo le occorrenze dell'autore del tweet retwittato
if "retweeted_status" in tweet:
screen_name = tweet["retweeted_status"]["user"]["screen_name"]
if screen_name not in users_nodes:
users_nodes[screen_name] = 1
else:
users_nodes[screen_name] += 1
# Calcolo le co-occorrenze degli hashtag
for h1 in tweet_hashtags: # Ciclo sugli hashtag: A, B, C
for h2 in tweet_hashtags: # Ciclo sugli hashtag: A, B, C
if h2["text"] != h1["text"]: # Considero solo gli hashtag diversi
# Ordino la coppia di hashtag in ordine alfabetico
if h2["text"] > h1["text"]:
hashtags_edge_key = h1["text"] + "," + h2["text"]
else:
hashtags_edge_key = h2["text"] + "," + h1["text"]
if hashtags_edge_key not in hashtags_edges:
hashtags_edges[hashtags_edge_key] = 1
else:
hashtags_edges[hashtags_edge_key] += 1
# Calcolo le co-occorrenze delle menzioni
for u1 in tweet_mentions: # Ciclo sulle menzioni: A, B, C
# Ordino la coppia autore / menzione in ordine alfabetico
if tweet["user"]["screen_name"] > u1["screen_name"]:
mentions_edge_key = u1["screen_name"] + "," + tweet["user"]["screen_name"]
else:
mentions_edge_key = tweet["user"]["screen_name"] + "," + u1["screen_name"]
if mentions_edge_key not in users_edges:
users_edges[mentions_edge_key] = 2
else:
users_edges[mentions_edge_key] += 2
for u2 in tweet_mentions: # Ciclo sulle menzioni: A, B, C
if u2["screen_name"] != u1["screen_name"]: # Considero solo le menzioni diverse
# Ordino la coppia di menzioni in ordine alfabetico
if u2["screen_name"] > u1["screen_name"]:
mentions_edge_key = u1["screen_name"] + "," + u2["screen_name"]
else:
mentions_edge_key = u2["screen_name"] + "," + u1["screen_name"]
if mentions_edge_key not in users_edges:
users_edges[mentions_edge_key] = 1
else:
users_edges[mentions_edge_key] += 1
with open("hashtags_nodes.csv", "w") as f:
f.write("Id,Label,Weight\n")
for key in hashtags_nodes:
if hashtags_nodes[key] > 1:
try:
f.write(key + "," + key + "," + str(hashtags_nodes[key]) + "\n")
except:
continue
with open("hashtags_edges.csv", "w") as f:
f.write("Source,Target,Weight\n")
for key in hashtags_edges:
if hashtags_edges[key]//2 > 1:
try:
f.write(key + "," + str(hashtags_edges[key]//2) + "\n")
except:
continue
with open("users_nodes.csv", "w") as f:
f.write("Id,Label,Weight\n")
for key in users_nodes:
if users_nodes[key] > 1:
try:
f.write(key + "," + key + "," + str(users_nodes[key]) + "\n")
except:
continue
with open("users_edges.csv", "w") as f:
f.write("Source,Target,Weight\n")
for key in users_edges:
if users_edges[key]//2 > 1:
try:
f.write(key + "," + str(users_edges[key]//2) + "\n")
except:
continue
